
Voorbereidingen
Voor deze analyses maken we gebruik van python en van een aantal packages. Heb je deze nog niet geïnstalleerd op jouw computer? Dit kun je gemakkelijk doen met 'pip install', zoals 'pip install seaborn'.
import pandas as pd
import numpy as np
# voor visualisatie:
import matplotlib.pyplot as plt
import seaborn as sns
Daarnaast maken we gebruik van een dummy-set. Deze kun je hier downloaden: Facturen.
Dit lezen we vervolgens in in een dataframe:
file_path = "dummy_invoices_products.csv"
df = pd.read_csv(file_path, sep=";", encoding="utf-8")
1. Prijsontwikkeling van goederen over tijd
Door de prijsontwikkeling over tijd te analyseren, kun je ongebruikelijke schommelingen in de kosten detecteren. Dit helpt bij het identificeren van prijsverhogingen die mogelijk niet goedgekeurd zijn of die wijzen op veranderingen in de markt.
Allereerst prepareren we de data; datumveld correct zetten en stuksprijs berekenen:
# Zet de datumkolom om naar datetime-formaat voor tijdsanalyses
df['Issue Date'] = pd.to_datetime(df['Issue Date'], format='%d-%m-%Y')
# Bereken de prijs per eenheid
df['UnitPrice'] = df['InvoiceAmount'] / df['InvoiceQuantity']
Daarna visualiseren we de data door de prijzen per product over de tijd te plaatsen met een lijndiagram.
# Visualiseer de prijsontwikkeling voor de geselecteerde producten
plt.figure(figsize=(12,6))
sns.lineplot(data=df, x='Issue Date', y='UnitPrice', hue='ItemName', marker='o')
plt.title('Prijsontwikkeling van geselecteerde producten')
plt.xlabel('Datum')
plt.ylabel('Prijs per eenheid')
plt.xticks(rotation=45)
plt.show()
Resultaat:
Hieronder zie je het diagram dat er uit komt.
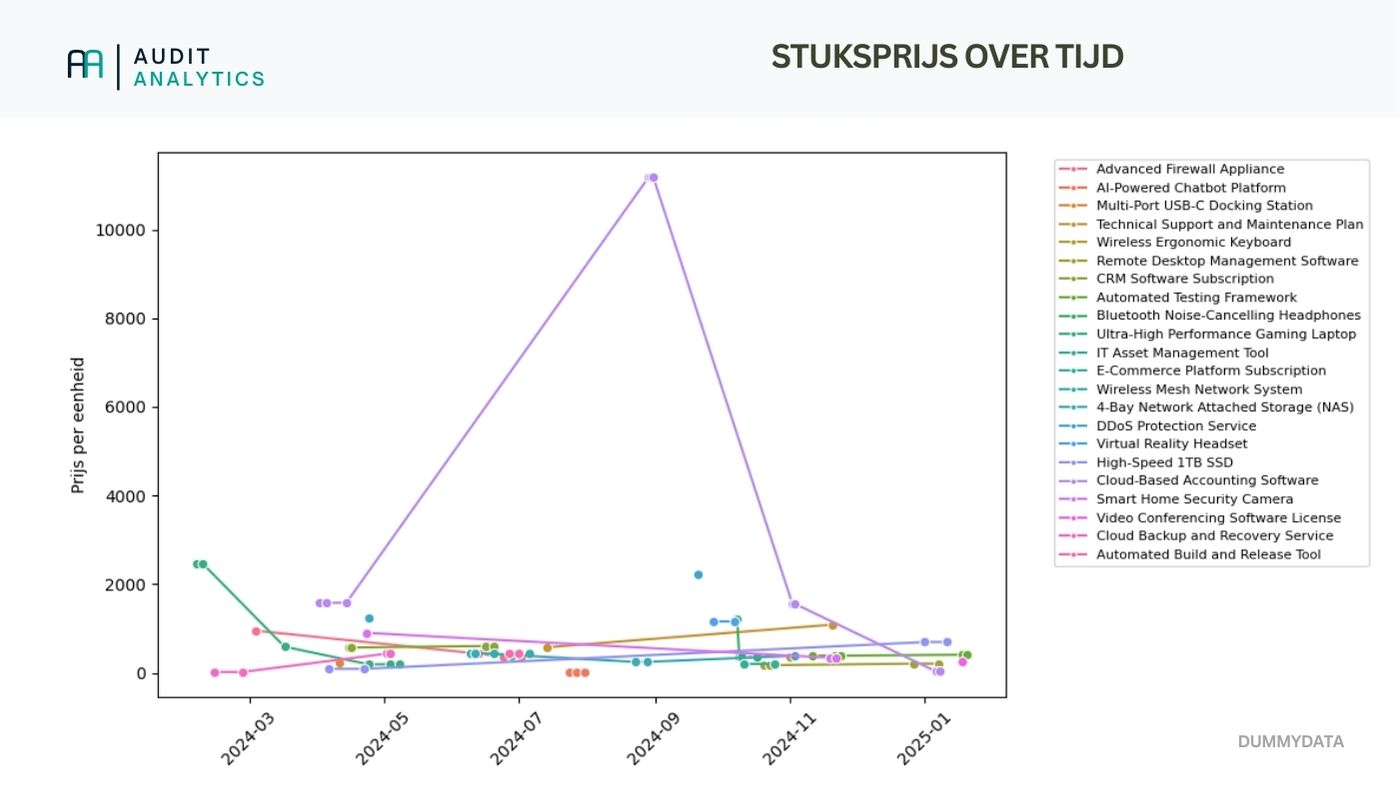
Dit kan een beetje overweldigend zijn doordat het best wat producten zijn (laat staan voor een productie-set). Toch kun je hier al wel wat patronen ontdekken. Eventueel kun je ook inzoomen op enkele vaak ingekochte of cruciale producten.
2. Vergelijking tussen leveranciers
Het vergelijken van leveranciers kan je helpen bij het identificeren van inconsistenties en mogelijke overfacturering. Als dezelfde producten door verschillende leveranciers sterk variëren in prijs, kan dit duiden op inefficiënties of zelfs fraude.
# Bereken de gemiddelde prijs per leverancier voor elk product
df_avg_price = df.groupby(['VendorID', 'ItemName'])['UnitPrice'].mean().reset_index()
# Bereken het maximale en minimale prijsverschil per product tussen leveranciers
df_price_diff = df.groupby(['ItemName', 'VendorID'])['UnitPrice'].mean().reset_index()
df_price_range = df_price_diff.groupby('ItemName')['UnitPrice'].agg(['min', 'max'])
df_price_range['PriceDifference'] = df_price_range['max'] - df_price_range['min']
We hebben nu inzichtelijk welke producten de grootste prijsverschillen kennen. Vervolgens zou ik aanraden om te duiden op de grootste verschillen en deze daarna eventueel te visualiseren.
# Sorteer op grootste prijsverschil en toon de top 10 producten
df_largest_differences = df_price_range.sort_values(by='PriceDifference', ascending=False).head(10)
# Selecteer een subset van producten om het overzicht duidelijker te maken
selected_products = ['Cloud-Based Accounting Software','Ultra-High Performance Gaming Laptop', 'Bluetooth Noise-Cancelling Headphones', 'High-Speed 1TB SSD']
df_avg_price_filtered = df_avg_price[df_avg_price['ItemName'].isin(selected_products)]
# Visualiseer de prijsverschillen tussen leveranciers voor de geselecteerde producten
plt.figure(figsize=(12,6))
sns.boxplot(data=df_avg_price_filtered, x='ItemName', y='UnitPrice', hue='VendorID')
plt.title('Vergelijking inkoopprijzen tussen leveranciers (geselecteerde producten)')
plt.xticks(rotation=45)
plt.show()
Resultaat:
Hieronder zie je de headmap die er uit komt.
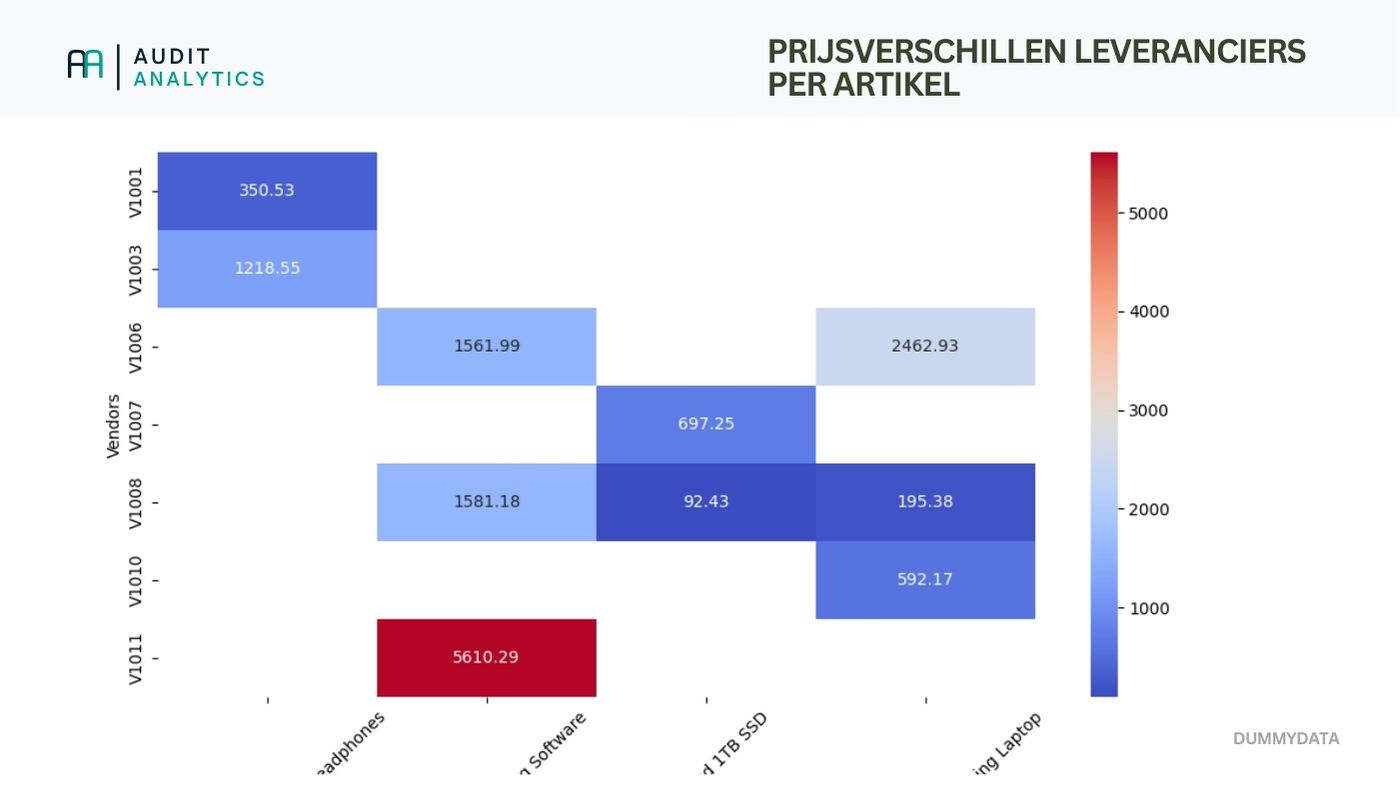
Dit is uiteraard met dummy-data en daardoor wat grote verschuivingen. Toch hoop ik dat duidelijk is dat je hiermee wel goed inzichtelijk kunt maken hoe de verschillen zijn opgebouwd.
3. Identificeren van leveranciers met systematisch hogere prijzen
Door te identificeren welke leveranciers systematisch hogere prijzen hanteren, zou je kunnen bepalen of contractuele afspraken worden nageleefd en of prijsafspraken wel gunstig zijn.
# Bereken de gemiddelde prijs per leverancier
df_vendor_avg = df.groupby('VendorID')['UnitPrice'].mean().reset_index()
# Sorteer de leveranciers op basis van de gemiddelde prijs
df_vendor_avg = df_vendor_avg.sort_values(by='UnitPrice', ascending=False)
# Visualiseer de leveranciers met de hoogste prijzen
plt.figure(figsize=(10,5))
sns.barplot(data=df_vendor_avg, x='VendorID', y='UnitPrice')
plt.title('Gemiddelde prijs per leverancier')
plt.xticks(rotation=45)
plt.show()
Uiteraard moet je (zoals altijd) wel kritisch zijn bij deze uitkomsten. Wanneer een bedrijf veel verschillende inkoopprijzen kent vanwege een breed scala aan producten, hoeft een sterke afwijking hier niet direct wat te zeggen.
4. Detecteren van outliers in prijzen
We hebben nu gekeken naar de prijzen over tijd en tussen de leveranciers, maar we kunnen ook nog kijken naar prijzen zelf. We gaan kijken naar de outliers. Een outlier is een waarde in een dataset die significant afwijkt van de rest van de gegevens. Dit kan betekenen dat de waarde extreem hoog of laag is in vergelijking met het gemiddelde.Outliers in prijzen kunnen duiden op fouten of ongebruikelijke prijsafspraken. Hieronder berekenen we de Z-score van de stuksprijzen en geven degene terug met een score die groter is dan 3. De Z-score is een statistische maat die aangeeft hoe ver een specifieke waarde afwijkt van het gemiddelde in een dataset, uitgedrukt in standaarddeviaties:
# Bereken de Z-score van de eenheidsprijzen
df['Z-Score'] = zscore(df['UnitPrice'])
# Selecteer de outliers met een Z-score groter dan 3 (sterk afwijkend)
outliers = df[df['Z-Score'].abs() > 3]
Resultaat
Het kwam in de analyse al wel vaker naar voren, maar de Cloud-Based Accounting Software van leverancier V1011 wijkt wel erg af van de andere stuksprijzen:
VendorID ItemName UnitPrice Z-Score
38 V1011 Cloud-Based Accounting Software 11183.403433 4.830462
39 V1011 Cloud-Based Accounting Software 11183.403433 4.830462
40 V1011 Cloud-Based Accounting Software 11183.403433 4.830462
Conclusie
In dit artikel hebben we met vier simpele analyses de inkoopprijzen onder handen genomen. Dit hebben we weliswaar met dummydata gedaan, maaar hopelijk kun jij dit gebruiken als inspiratie!


